有限状态机,一种抽象的理论模型。
有限状态机**(Finite State Machine)**通过可构造、可验证的方式来呈现有限个变量所描述的状态变化过程。比如,封闭的有向图。它可以通过if-else, switch-case和函数指针来实现,从软件工程角度看,主要是为了封装逻辑。
带有状态转移的有限状态机示例:
STATE_MACHINE() {
State cur_State = type_A;
while (cur_State != type_C) {
Package _pack = getNewPackage();
switch() {
case type_A:
process_pkg_state_A(_pack);
cur_State = type_B;
break;
case type_B:
process_pkg_state_B(_pack);
cur_State = type_C;
break;
}
}
}
|
该状态机包含三种状态:type_A,type_B和type_C。其中,type_A是初始状态,type_C是结束状态。状态机的当前状态记录在cur_State变量中,逻辑处理时,状态机先通过getNewPackage获取数据包,然后根据当前状态对数据进行处理,处理完后,状态机通过改变cur_State完成状态转移。
有限状态机是一种逻辑单元内部的高效编程方法,在服务器编程中,服务器可以根据不同状态或者消息类型进行相应的处理逻辑,使得程序逻辑清晰易懂。
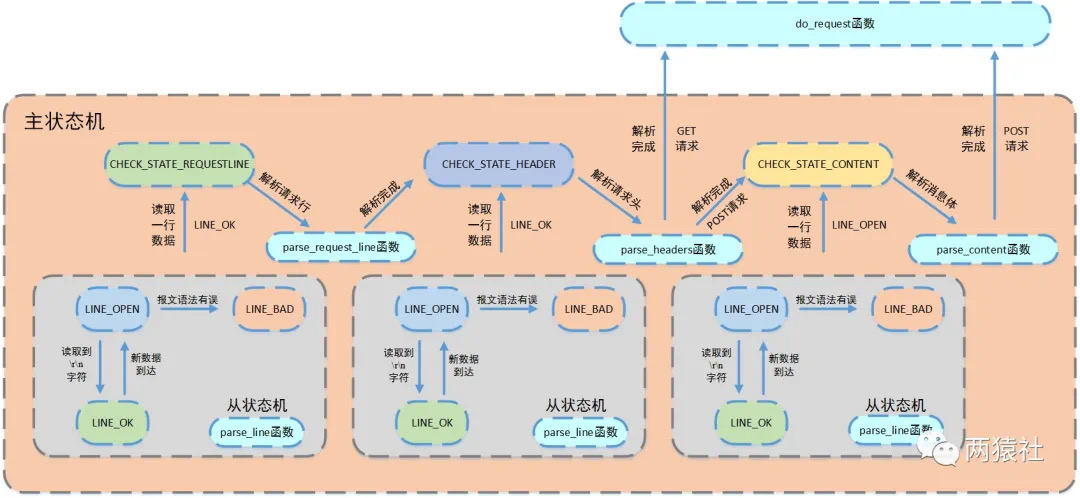
基于状态机来处理webserver http报文
http报文处理流程:
- 浏览器端发出http连接请求,主线程创建http对象接收请求并将所有数据读入对应buffer,将该对象插入任务队列,工作线程从任务队列中取出一个任务进行处理。
- 工作线程取出任务后,调用process_read函数,通过主、从状态机对请求报文进行解析。
- 解析完之后,跳转do_request函数生成响应报文,通过process_write写入buffer,返回给浏览器端。
定义http类
class http_conn {
public:
static const int FILENAME_LEN=200;
static const int READ_BUFFER_SIZE=2048;
static const int WRITE_BUFFER_SIZE=1024;
enum METHOD{GET=0, POST, HEAD, PUT, DELETE, TRACE, OPTIONS, CONNECT, PATH};
enum CHECK_STATE{CHECK_STATE_REQUESTLINE=0, CHECK_STATE_HEADER, CHECK_STATE_CONTENT};
enum HTTP_CODE {NO_REQUEST, GET_REQUEST, BAD_REQUEST, NO_RESOURCE, FORBIDDEN_REQUEST, FILE_REQUEST, INTERNAL_ERROR, CLOSED_CONNECTION};
enum LINE_STATUS{LINE_OK=0, LINE_BAD, LINE_OPEN};
public:
http_conn(){}
~http_conn(){}
public:
void init(int sockfd, const sockaddr_in &addr);
void close_conn(bool real_close = true);
void process();
bool read_once();
bool write();
sockaddr_in *get_address() {
return &m_address;
}
void initmysql_result();
void initresultFile(connection_pool *connPool);
private:
void init();
HTTP_CODE process_read();
bool process_write(HTTP_CODE ret);
HTTP_CODE parse_request_line(char *text);
HTTP_CODE parse_headers(char *text);
HTTP_CODE parse_content(char *text);
HTTP_CODE do_request();
char* get_line() { return m_read_buf + m_start_line; };
LINE_STATUS parse_line();
void unmap();
bool add_response(const char* format, ...);
bool add_content(const char* content);
bool add_status_line(int status, const char* title);
bool add_headers(int content_length);
bool add_content_type();
bool add_content_length(int content_length);
bool add_linger();
bool add_blank_line();
public:
static int m_epollfd;
static int m_user_count;
MYSQL *mysql;
private:
int m_sockfd;
sockaddr_in m_address;
char m_read_buf[READ_BUFFER_SIZE];
int m_read_idx;
int m_checked_idx;
int m_start_line;
char m_write_buf[WRITE_BUFFER_SIZE];
int m_write_idx;
CHECK_STATE m_check_state;
METHOD m_method;
char m_real_file[FILENAME_LEN];
char *m_url;
char *m_version;
char *m_host;
int m_content_length;
bool m_linger;
char *m_file_address;
struct stat m_file_stat;
struct iovec m_iv[2];
int m_iv_count;
int cgi;
char *m_string;
int bytes_to_send;
int bytes_have_send;
};
|
报文解析流程
void http_conn::process() {
HTTP_CODE read_ret = process_read();
if (read_ret == NO_REQUEST) {
modfd(m_epollfd, m_sockfd, EPOLLIN);
return;
}
bool write_ret=process_write(read_ret);
if (!write_ret) {
close_conn();
}
modfd(m_epollfd, m_sockfd, EPOLLOUT);
}
|
process_read通过while循环,将主从状态机进行封装,对报文的每一行进行循环处理。
判断条件
- 主状态机转移到CHECK_STATE_CONTENT,该条件涉及解析消息体
- 从状态机转移到LINE_OK,该条件涉及解析请求行和请求头部
- 两者为或关系,当条件为真则继续循环,否则退出
循环体
- 从状态机读取数据
- 调用get_line函数,通过m_start_line将从状态机读取数据间接赋给text
- 主状态机解析text
char* get_line() {
return m_read_buf + m_start_line;
}
http_conn::HTTP_CODE http_conn::process_read() {
LINE_STATUS line_status = LINE_OK;
HTTP_CODE ret = NO_REQUEST;
char* text=0;
while ((m_check_state == CHECK_STATE_CONTENT && line_status == LINE_OK) || ((line_status = parse_line()) == LINE_OK)) {
text = get_line();
m_start_line = m_checked_idx;
switch (m_check_state) {
case CHECK_STATE_REQUESTLINE: {
ret = parse_request_line(text);
if (ret == BAD_REQUEST)
return BAD_REQUEST;
break;
}
case CHECK_STATE_HEADER: {
ret = parse_headers(text);
if (ret == BAD_REQUEST)
return BAD_REQUEST;
else if (ret == GET_REQUEST) {
return do_request();
}
break;
}
case CHECK_STATE_CONTENT: {
ret = parse_content(text);
if (ret == GET_REQUEST)
return do_request();
line_status = LINE_OPEN;
break;
}
default:
return INTERNAL_ERROR;
}
}
return NO_REQUEST;
}
|
从状态机逻辑:
在HTTP报文中,每一行的数据由\r\n作为结束字符,空行则是仅仅是字符\r\n。因此,可以通过查找\r\n将报文拆解成单独的行进行解析。从状态机负责读取buffer中的数据,将每行数据末尾的\r\n置为\0\0,并更新从状态机在buffer中读取的位置m_checked_idx,以此来驱动主状态机解析。
http_conn::LINE_STATUS http_conn::parse_line() {
char temp;
for (; m_checked_idx < m_read_idx; ++m_checked_idx) {
temp = m_read_buf[m_checked_idx];
if (temp == '\r') {
if ((m_checked_idx + 1) == m_read_idx)
return LINE_OPEN;
else if (m_read_buf[m_checked_idx + 1] == '\n') {
m_read_buf[m_checked_idx++] = '\0';
m_read_buf[m_checked_idx++] = '\0';
return LINE_OK;
}
return LINE_BAD;
}
else if (temp == '\n') {
if (m_checked_idx > 1 && m_read_buf[m_checked_idx - 1] == '\r') {
m_read_buf[m_checked_idx-1] = '\0';
m_read_buf[m_checked_idx++] = '\0';
return LINE_OK;
}
return LINE_BAD;
}
}
return LINE_OPEN;
}
|
主状态机逻辑
主状态机初始状态是CHECK_STATE_REQUESTLINE,通过调用从状态机来驱动主状态机,在主状态机进行解析前,从状态机已经将每一行的末尾\r\n符号改为\0\0,以便于主状态机直接取出对应字符串进行处理。
- CHECK_STATE_REQUESTLINE
- 主状态机的初始状态,调用parse_request_line函数解析请求行
- 解析函数从m_read_buf中解析HTTP请求行,获得请求方法、目标URL及HTTP版本号
- 解析完成后主状态机的状态变为CHECK_STATE_HEADER
http_conn::HTTP_CODE http_conn::parse_request_line(char *text) {
m_url = strpbrk(text," \t");
if (!m_url) {
return BAD_REQUEST;
}
*m_url++ = '\0';
char *method = text;
if (strcasecmp(method, "GET") == 0)
m_method = GET;
else if (strcasecmp(method, "POST") == 0) {
m_method = POST;
cgi = 1;
}
else
return BAD_REQUEST;
m_url += strspn(m_url, " \t");
m_version = strpbrk(m_url, " \t");
if (!m_version)
return BAD_REQUEST;
*m_version++ = '\0';
m_version += strspn(m_version, " \t");
if (strcasecmp(m_version, "HTTP/1.1") != 0)
return BAD_REQUEST;
if (strncasecmp(m_url, "http://",7) == 0) {
m_url += 7;
m_url = strchr(m_url, '/');
}
if (strncasecmp(m_url, "https://", 8) == 0) {
m_url += 8;
m_url = strchr(m_url, '/');
}
if (!m_url || m_url[0] != '/')
return BAD_REQUEST;
if (strlen(m_url) == 1)
strcat(m_url, "judge.html");
m_check_state = CHECK_STATE_HEADER;
return NO_REQUEST;
}
|
解析请求头
http_conn::HTTP_CODE http_conn::parse_headers(char *text) {
if (text[0] == '\0') {
if (m_content_length != 0) {
m_check_state = CHECK_STATE_CONTENT;
return NO_REQUEST;
}
return GET_REQUEST;
}
else if (strncasecmp(text, "Connection:", 11) == 0) {
text += 11;
text += strspn(text, " \t");
if (strcasecmp(text, "keep-alive") == 0) {
m_linger = true;
}
}
else if (strncasecmp(text, "Content-length:", 15) == 0) {
text += 15;
text += strspn(text," \t");
m_content_length = atol(text);
}
else if (strncasecmp(text, "Host:", 5) == 0) {
text += 5;
text += strspn(text, " \t");
m_host = text;
} else {
printf("oop!unknow header: %s\n", text);
}
return NO_REQUEST;
}
|
解析消息体
http_conn::HTTP_CODE http_conn::parse_content(char *text) {
if (m_read_idx >= (m_content_length + m_checked_idx)) {
text[m_content_length]='\0';
m_string = text;
return GET_REQUEST;
}
return NO_REQUEST;
}
|
 wechat
wechat alipay
alipay



